Data quality management procedure 📊
QALITA Platform puts data quality management at the center 🎯 of its operation. This management is ensured and facilitated by a set of functionalities that enable :
- Measure data quality 📏 and create analysis reports.
- Detect anomalies 🔍 and translate them into action.
- Take corrective action 🔧 and monitor its execution, measure its impact.
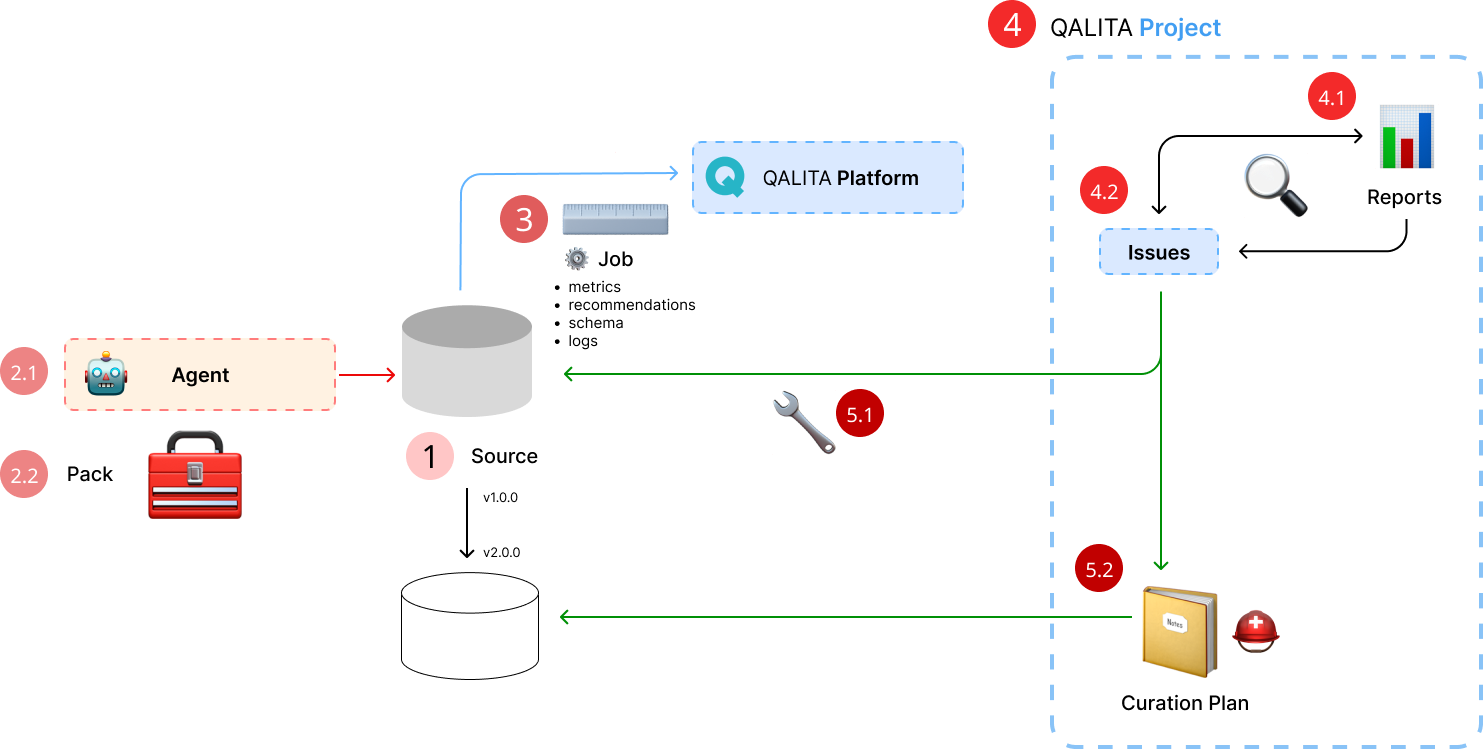
Data management procedure
Measuring data quality (1/2/3) 📈
1 Source
The first step is to reference the source to be measured in the platform.
This step is performed by a data engineer using the command line qalita-cli.
2.1 Agent
The second step is to register an agent capable of communicating with the source.
This step is also performed by a data engineer using the qalita-cli command line.
2.2 Pack
The next step is to create a pack to measure data quality.
This step is also performed by a data engineer or data analyst using the command line qalita-cli.
Packs are categorized according to the type of analysis they produce, for example: pack:quality:completeness to measure data completeness.
QALITA Platform offers a set of default packs, but it is possible to create new ones.
QALITA Platform supports the following type packs:
completeness: Measures data completeness.validity: Measures data validity.Accuracy: Measures data accuracy.timeliness: Measures the timeliness of data.Consistency: Measures data consistency.uniqueness: Measures data uniqueness.reasonability: Measures the reasonability of the data.
3 Analysis
The final step is to run an analysis on the source. This step is performed by a data engineer using the command line qalita-cli. The analysis is performed using a pack and an agent. It produces metadata stored in the QALITA Platform database.
- metrics: metrics are indicators of data quality. They are calculated by the pack from the source data.
- recommendations: recommendations are suggestions for improvement raised by the pack's analysis of the source.
- schema: the schema is the description of the data structure. It enables metrics and recommendations to be associated with
perimetersof data. - logs: logs are the traces of the analysis. They enable you to understand the calculations performed by the pack.
Anomaly detection (4) 🔎
Anomalies are detected by a data analyst or data manager using QALITA Platform's graphical interface. Anomalies are detected on the basis of the metrics and recommendations produced by the analyses. They are then associated with a ticket.
4 Projects
For better organization, you can create projects which group together sources and analyses.
A project groups together :
- One or more data sources referenced in the platform.
- Data quality analysis reports.
- Tickets associated with the project's data sources.
- Data curation plans.
This can be particularly useful for data migration projects or for research projects involving several data sources.
4.1 Reports
Analysis reports are reports that allow you to view the metadata of sources linked to a project.
They are generated by QALITA Platform, and can be configured to display metrics and recommendations for one or more packs, on one or more sources. They can also be shared, to facilitate information sharing and collaboration between the various players in a project.
see the Reports page for more information
4.2 Tickets
Tickets are anomalies detected by a data analyst or a data manager. They are associated with a data source. They are created from metrics and recommendations in analysis reports.
Recommendations are categorized according to their criticality:
High : Data is unusable. Warning: Data are usable but with risks. Info : Data is usable but with limited risk.
Tickets are used to track anomalies and associated corrective actions. They can be managed directly from the platform or from a project management tool such as Jira or Trello, thanks to QALITA Platform's integration with these tools
Corrective actions (5) 🛠️
there are two possible types of anomaly:
- The anomaly is human, (bad input, bad configuration, etc...) The data is bad at source, it must be corrected.
- The anomaly is due to a technical problem, the data is bad after transformation, it must be transformed, scaled, the ETL programs must be corrected.
5.1 Technical
If the anomaly is technical, QALITA Platform cannot correct it directly. The ETL program causing the fault must be corrected. This can be done by a data engineer. However, a data analyst or data manager can monitor the correction using tickets. A new analysis can then be launched to check that the correction has been taken into account.
5.2 Human
If the anomaly is human, QALITA Platform allows you to correct it directly.
To do this, you need to create a curation plan for the data. A curation plan is a set of corrective actions designed to remedy an anomaly. It is created by a data analyst or a data manager using QALITA Platform's graphical interface.
The original source is copied, then the corrective actions are applied to the copy. This keeps the original source intact. A new version of the source is then created. This new version is then analyzed to check that the corrective actions have been taken into account.
This feature is currently under development. It is scheduled for release by the end of 2024.